机器学习,去年学的,学了没用过,今年忘了,有空抽时间复习一遍OwO
基础知识
参考阅读:
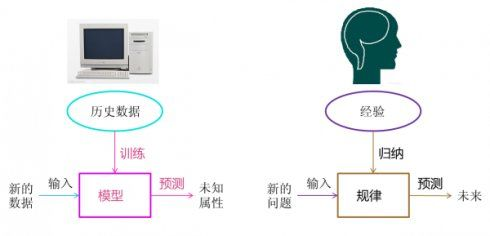
🔷 机器学习的三要素:数据、算法、模型
机器学习研究的是从数据中通过选取合适的算法,自动的归纳逻辑或规则,并根据归纳的结果(模型)与新数据来进行预测
计算机利用已有的数据 👉 得出某种模型 👉 并利用此模型预测未来
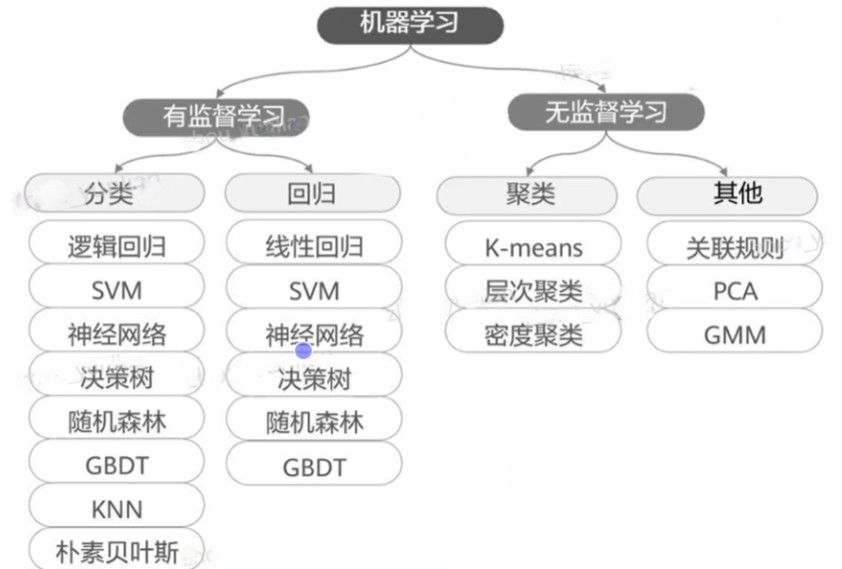
监督学习、无监督学习
参考阅读:
监督学习
向计算机提供数据和这些数据所对应“标签”(label),
监督学习中的 “ 标签 ” 就是起到一个监督的作用
例如:线性回归、神经网络、决策树、支持向量机、KNN、朴素贝叶斯算法
非监督学习
不提供数据所对应的标签信息,计算机通过观察各种数据之间的特性,发现特性背后的规律
例如:主成分分析法(PCA)、异常检测法、自编码算法、深度信念网络、赫比学习法、生成式对抗网络、自组织映射网络
半监督学习
综合监督学习和非监督学习的特征。它主要考虑如何使用少量的 有标签样本 和 大量的没有标签的样本 进行训练和分类。
聚类、分类、回归
聚类
什么是聚类?
在没有训练的条件下,对一些没有标签的数据进行归纳分类。根据相似性对数据进行分组,以便对数据进行概括。
聚类的时候,并不关心某一类是什么,实现的只是将相似的东西聚在一起。
总的来说,聚类就是对大量未知标注的数据集,按数据内在的相似性将数据集划分为多个类别,使类别内的数据相似度较大,类别间的数据相似度较小。
无监督学习
聚类的目标
同一类中,类内对象是相似的(或是相关的);不同类中的对象是不同的(不相关的)。
聚类方法好坏的判定:
产生高质量的聚类结果——簇。簇内有高相似性,簇间有低的相似性。
取决于聚类方法采用的相似性评估方法以及该方法的具体实现。
取决于聚类方法能否发现某些/所有的隐含模式。
分类
什么是分类?
监督学习,根据一些给定的已知类别的样本(即有标签的数据),使计算机能够对未知类别的样本进行分类。分类要求必须事先明确知道各类别的信息,是一种对离散型随机变量建模或预测的监督学习算法。
分类算法的局限
要求:必须事先明确指导各个类别的信息,并且所有待分类样本都要有一个类别与之对应。
但是很多时候这些条件并不能满足,尤其是在处理海量数据时,如果通过预处理使得数据满足分类算法的要求,代价会非常大,这时候可以考虑使用聚类算法。
聚类与分类的区别
首先,聚类是非监督学习,分类是监督学习。
二者的本质区别就是
对于聚类来说,是不知道样本的类别信息的,只能凭借样本在特征空间的分布来分析样本的属性;
对于分类来说,知道样本的类别信息是必要的,根据已知训练样本的类别信息,让计算机自己学着知道每个类别的特点,然后对未知类别的数据进行分类。
回归
什么是回归?
监督学习,也需要先向计算机输入数据的训练样本让计算机学习。
与分类的区别是:回归方法是一种对数值型连续随机变量进行预测和建模的监督学习算法,产生的结果一般也是数值型的
回归任务的特点
标注的数据集具有数值型的目标变量。
也就是说,每一个观察样本都有一个数值型的标注真值以监督算法。
🔴简单的判别方法:给定一个样本特征,希望预测其对应的属性值
如果是离散的,那么就是分类问题。
如果是连续的数据,就是回归问题。
给定一组样本特征,没有对应的属性值,而是想发觉这组样本的空间分布
- 比如分析哪些样本靠的更近,那些样本之间里的很远,这就是聚类问题。
机器学习在实际生活中有哪些应用?
基础机器学习算法
简单说说一些数据挖掘的算法,就决策树,朴素贝叶斯,K-means,KNN这些
逻辑回归
线性回归
K-means
k-means的优点和缺点